 Python Code
Dec 06, 2023
Python Code
Dec 06, 2023
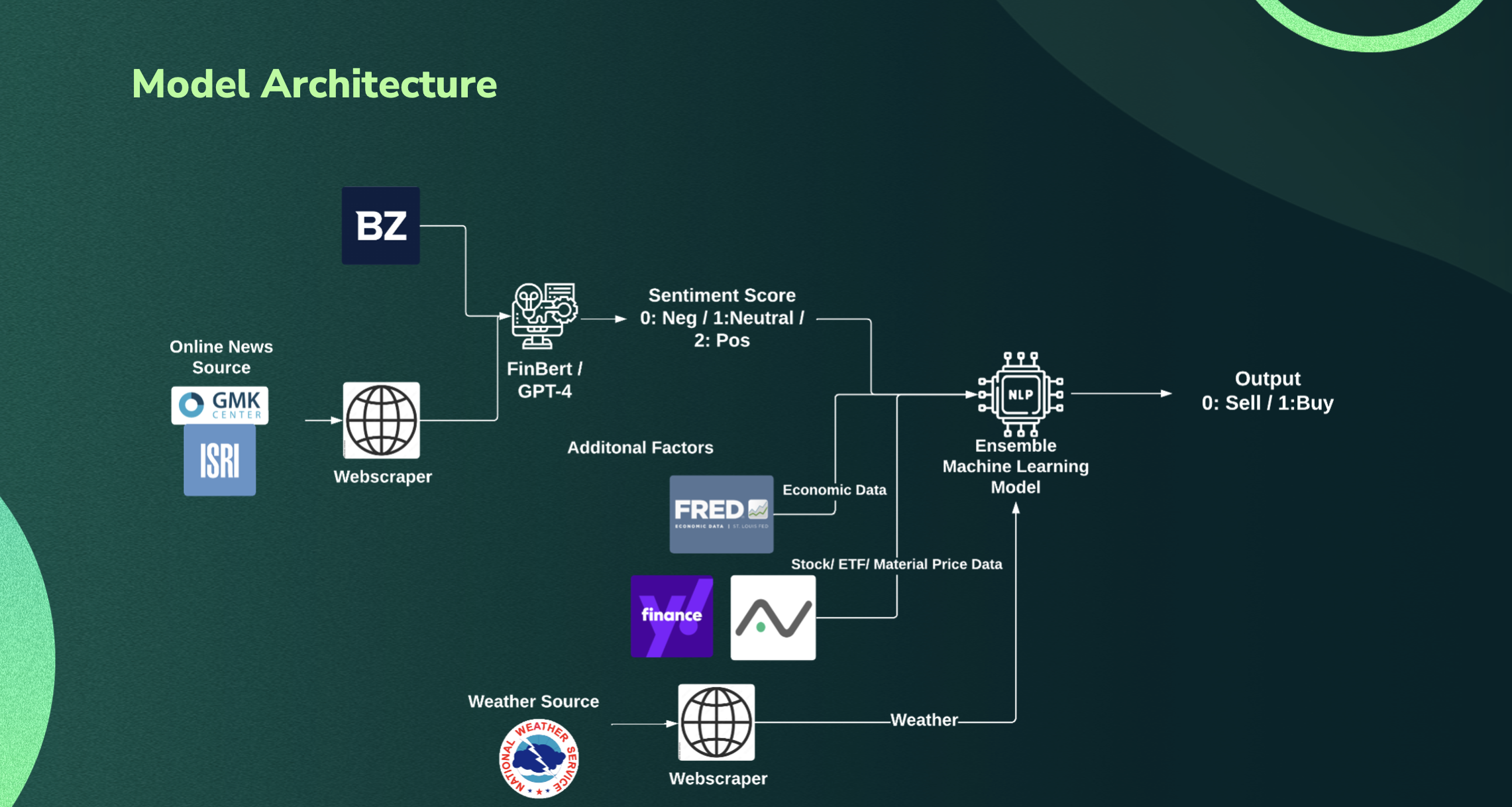
This project focuses on analyzing financial news sentiment and utilizing machine learning models to predict stock prices based on the sentiment analysis.
It integrates data from various sources, including financial news articles, stock prices, economic indicators, and weather data.
The sentiment analysis is performed using two models: FinBert and GPT (Generative Pre-trained Transformer).
The machine learning model for price prediction employs the CatBoost algorithm.
 Python Code
May 20, 2023
Python Code
May 20, 2023
In this project, I excelled in a Kaggle competition, ranking in the top 5%, for predicting software defects.
I employed advanced data exploration, innovative feature engineering, and ensemble modeling with LightGBM, XGBoost,
CatBoost, and Random Forest, resulting in a robust predictive solution.
This project underscores my expertise in data analysis, feature engineering, and predictive modeling, demonstrating my ability to tackle complex real-world challenges effectively.
 Python Code
May 20, 2023
Python Code
May 20, 2023
This data science project involves regression analysis using two models: LADRegression and LightGBM.
The project includes data preprocessing, feature engineering using Principal Component Analysis (PCA) and Partial Least Squares (PLS) regression, hyperparameter tuning using grid search, and model evaluation.
In particular, the project performs several predictions using different models, and then stacks them using Least Additive Regression with positive parameters.
The goal is to develop accurate regression models and optimize their performance on the given dataset.
I created this notebook for a Kaggle Competition, where I resulted in the top 1.5% of the leaderboard.
 Python Code
May 16, 2023
Python Code
May 16, 2023
As you're undoubtedly aware, the vast volume of news and rumors that emerge daily can be overwhelming, rendering it practically impossible for an individual to thoroughly process each piece of information.
To counter this challenge, we have integrated cutting-edge LLMs to develop an innovative application designed to assist users in comprehending market sentiment.
Our application harnesses the power of user-specified sources, processing and analyzing vast amounts of data with exceptional accuracy.
It leverages the capabilities of LSTM models, a type of recurrent neural network well-suited for sequence prediction problems, to predict market trends.
This integration of LLMs and LSTM models provides a robust and comprehensive solution to keep up with the pace of real-time information flow, resulting in a powerful tool for understanding and predicting market sentiment.
The ultimate goal is to empower our users to make informed decisions based on accurate, up-to-date, and predictive insights. (Initially built for Tribe AI Hackathon)
 Python Code
May 2, 2023
Python Code
May 2, 2023
This project is a Flask interactive web application that displays a map of New York City and allows users to query it, along with a recommendation algorithm that matches suppliers to restuarants.
The application uses a combination of Python, html, css, and Javascript. The data is stored using Apache Spark and MongoDB.

 R Code
April 30, 2023
R Code
April 30, 2023
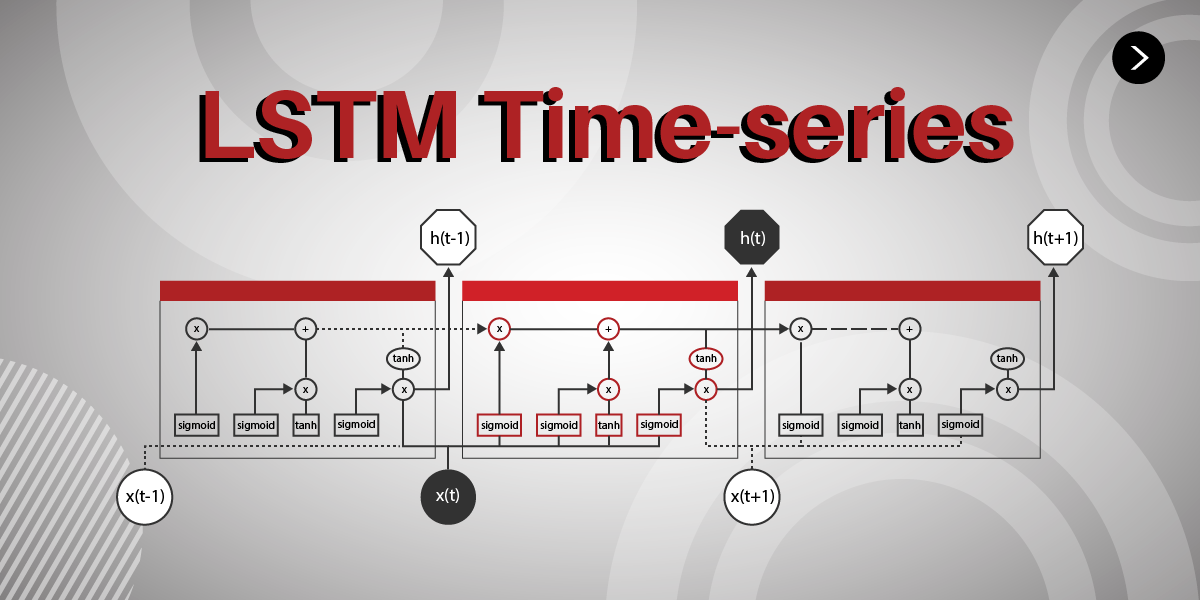
In this data science project I predicted the the fluctuation of Tesla Stock from Elon Musk Tweets.
The goal of this project was to predict if the stock would decrease or increase based on the previous day's Elon Musk tweets.
To achieve this, I used first data preprocessing on the tweets column, which involved removing URLs, stripping whitespaces, removing non alpha characters, stemming words and creating a TF-IDF matrix.
Secondly, I performed exploratory analysis to visualize correlation between words and stock fluctuation, the top words used in the tweets, etc.
Then, I used feature engineering. Firstly I right merged the tesla stock dataset imported using Yahoo Finance API, then I grouped by day concatenating all the tweets that happened in the same day.
After that, I was able to extract some other useful information such as the number of tweets per day, the average length of the tweets, number of emoji used and so on.
After that, I performed sentiment analysis using vader, which provided useful sentiment scores.
Finally, I performed data modeling. For this step I used both a LSTM model on the stock data, and a neural network on the NLP data. Then, I combined the outputs with a second neural network to have one final layer with one output.
 Python Code
April 18, 2023
Python Code
April 18, 2023
In this data science project I predicted the number of weekly appointments for Columbia University. The goal of this project was to determine if there was a need to hire temporary staff based on the predicted appointment volume. To achieve this, I used first feature engineering, which involved analyzing changes in the characteristics of students over time. This helped me to identify patterns and trends that could affect the number of appointments. After performing the feature engineering, I used a deep learning model called a Long Short-Term Memory (LSTM) model to make predictions. The LSTM model was trained on the historical appointment data to learn from the patterns and trends in the data. Using the LSTM model, I was able to predict the weekly appointment volume for the next two months. This information can be used by Columbia University to make informed decisions about hiring temporary staff and managing resources efficiently.
Continue Reading Python Code
March 6, 2023
Python Code
March 6, 2023
In this project, I am using the pre-trained BERT (Bidirectional Encoder Representations from Transformers) model to classify tweets as either disaster-related or not. I train the model using a combination of cross-entropy loss and mixup regularization, and use early stopping to prevent overfitting. Overall, this project demonstrates the use of transfer learning and fine-tuning with BERT for natural language processing tasks.
Continue Reading Python Code
February 26, 2023
Python Code
February 26, 2023
The project predicts the popularity of recipes, recommending the system to show or less a certain recipe. This project involves data Validation, data cleaning, exploratory analysis, feature engineering, data modeling with Genetic Tuning algorithms, SGD Classification, XGBoost Classification, Random Forest Classification, and model stacking.
Continue Reading Python Code
February 15, 2023
Python Code
February 15, 2023
Created an application to automatize the extraction of data from the University database, data cleaning, feature engineering, and posting data to Google data studio. The application uses two main API endpoints: 12-Twenty and Google Cloud.
Continue Reading R Code
December 11, 2022
R Code
December 11, 2022
Performed feature engineering to mine, extract, and clean data from different variety of data. Modeled dataset, creating new features as a combination of existing ones to increase the correlation with the dependent variable. Split data in train and test and predicted using XGBoost model optimized with Bayes Optimization function.
Continue Reading R Code
November 05, 2022
R Code
November 05, 2022
Simulated thousands of data with R to validate assumptions about ESG's influence on consumption.
Continue Reading